Publications
2025
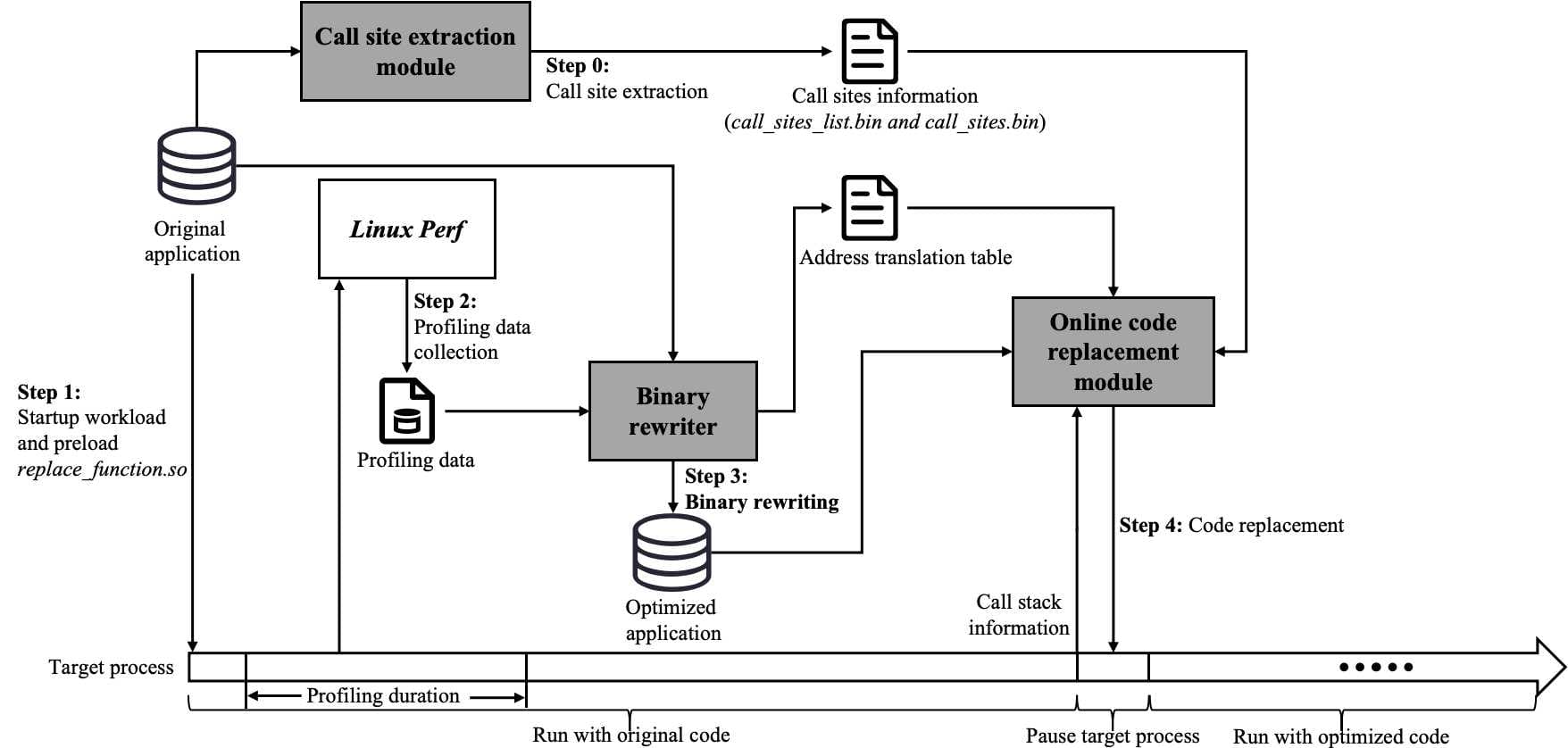
AOBO: A Fast-Switching Online Binary Optimizer on AArch64
ACM Transactions on Architecture and Code Optimization
·
16 May 2025
As the complexity of real-world server applications continues to grow, performance optimizations for large-scale applications are becoming increasingly challenging. The success of online optimization offered by OCOLOS and Dynimize proves that binary rewriting based on edge profiling data can significantly accelerate these applications. However, no similar online binary optimizer is currently available on the AArch64 platform. In response to the growing adoption of the AArch64 platform, this paper introduces AOBO, a fast-switching online binary optimizer specifically designed for AArch64. In addition to providing practical and efficient engineering support for AArch64-specific features, AOBO overcomes the challenge of lacking hardware counters for edge profiling on most commercially available AArch64 servers. In particular, AOBO embraces a novel edge weight estimation scheme to deliver more accurate edge estimation, which in turn allows AOBO’s binary rewriter to generate more efficient code. Furthermore, time spent on AOBO’s online code replacement stage is optimized to work at a subsecond level, thus enabling a fast switch from running the original binary to run the optimized one. We evaluate AOBO with CINT2017, GCC, MySQL and MongoDB, measuring the accuracy and coverage of the estimated edge weights, the performance improvements of the optimized binaries, and the online optimization cost. To make a fair comparison, we are using the performance data of the binaries generated by the default compilation scripts in the software packages as a baseline. Experimental data shows that AOBO can offer a more accurate edge weight estimation and generate binaries with superior performance. Furthermore, AOBO achieves online optimization with a very small overhead and significantly improves the performance of large-scale applications. Compared with the baselines, AOBO’s online optimization can achieve 24.7% and 31.11% performance improvement respectively for MySQL and MongoDB. Notably, application pause time is reduced from 1599.8 milliseconds to 462.1 milliseconds for MySQL, and from 1765.9 milliseconds to 507.1 milliseconds for MongoDB.
2024
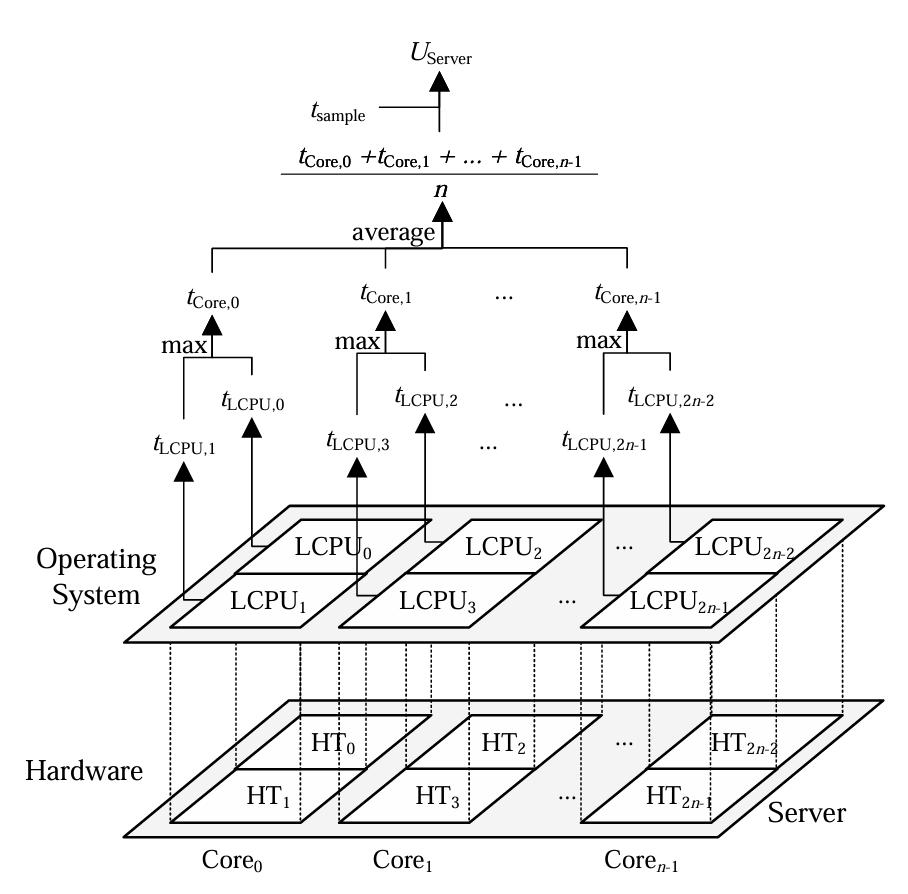
Retrospecting Available CPU Resources: SMT-Aware Scheduling to Prevent SLA Violations in Data Centers
IEEE Transactions on Parallel and Distributed Systems
·
08 Nov 2024
The paper focuses on an understudied yet fundamental problem: existing methods typically average the utilization of multiple hardware threads to evaluate the available CPU resources. However, the approach could underestimate the actual usage of the underlying physical core for Simultaneous Multi-Threading (SMT) processors, leading to an overestimation of remaining resources. The overestimation propagates from microarchitecture to operating systems and cloud schedulers, which may misguide scheduling decisions, exacerbate CPU overcommitment, and increase Service Level Agreement (SLA) violations. To address the potential overestimation problem, we propose an SMT-aware and purely data-driven approach named Remaining CPU (RCPU) that reserves more CPU resources to restrict CPU overcommitment and prevent SLA violations. RCPU requires only a few modifications to the existing cloud infrastructures and can be scaled up to large data centers. Extensive evaluations in the data center proved that RCPU contributes to a reduction of SLA violations by 18% on average for 98% of all latency-sensitive applications. Under a benchmarking experiment, we prove that RCPU increases the accuracy by 69% in terms of Mean Absolute Error (MAE) compared to the state-of-the-art

DeployFix: Dynamic Repair of Software Deployment Failures via Constraint Solving
(ASE'24) Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering
·
27 Oct 2024
Software deployment misconfiguration often happens and has been one of the major causes of deployment failures that give rise to service interruptions. However, there is currently no existing approach to automatically repairing deployment failures. We propose DeployFix, which automatically repairs software deployment failures via constraint solving in the dynamic-changing deployment environments. DeployFix first defines DeployIR as a unified intermediate representation to achieve the translation of heterogeneous specifications from different schedulers with different syntaxes. By reducing the root-cause analysis of deployment failures to the conflict resolution in propositional logic, DeployFix uses off-the-shelf constraint solvers to achieve automatic localization and diagnosis of conflicting constraints, which are the root causes of deployment failures. DeployFix finally resolves the conflicting constraints and generates repaired deployment configurations in terms of practical requirements. We evaluate DeployFix in both simulation and production environments with tens of thousands of nodes at Alibaba, on which tens of thousands of applications are running guided by hundreds of thousands of deployment constraints. Experimental results demonstrate that DeployFix outperforms the state of the art and it correctly repairs the deployment failures in minutes, even in a large production data center.
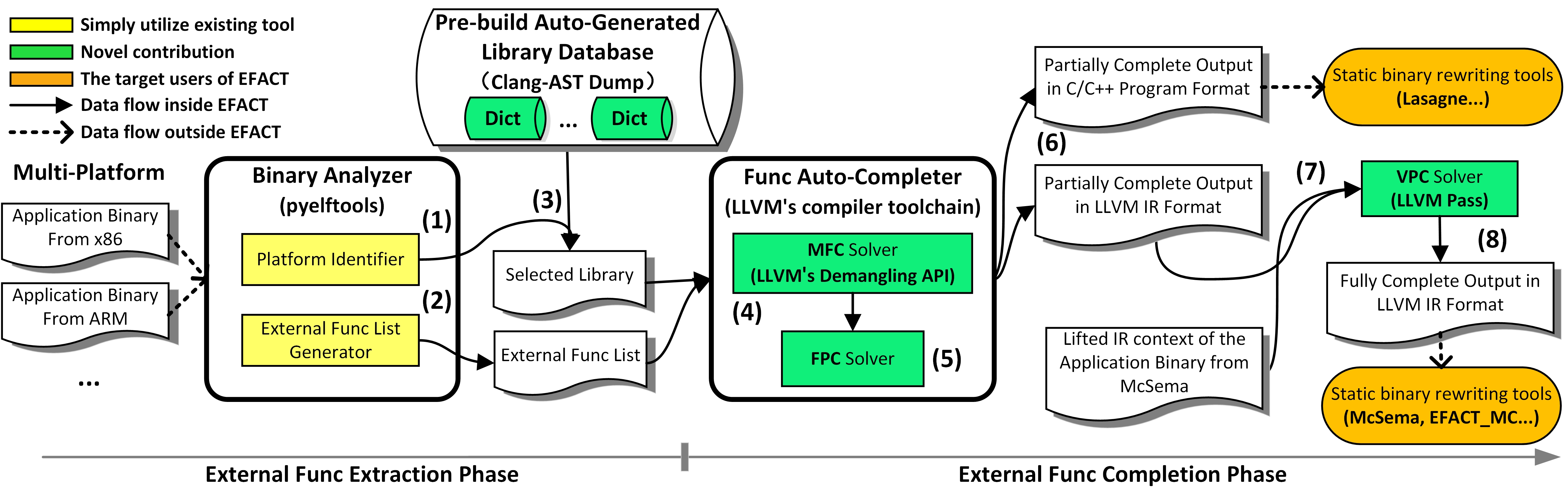
EFACT: An External Function Auto-Completion Tool to strengthen static binary lifting
Journal of Systems and Software
·
11 May 2024
Static binary lifting is essential in binary rewriting frameworks. Existing tools overlook the impact of External Function Completion (EXFC) in static binary lifting. EXFC recovers the declarations of External Functions (EXFs, functions defined in standard shared libraries) using only the function symbols available. Incorrect EXFC can misinterpret the source binary, or cause memory overflows in static binary translation, which eventually results in program crashes. Notably, existing tools struggle to recover the declarations of mangled EXFs originating from binaries compiled from C++. Moreover, they require time-consuming manual processing to support new libraries. This paper presents EFACT, an External Function Auto-Completion Tool for static binary lifting. Our EXF recovery algorithm better recovers the declarations of mangled EXFs, particularly addressing the template specialization mechanism in C++. EFACT is designed as a lightweight plugin to strengthen other static binary rewriting frameworks in EXFC. Our evaluation shows that EFACT outperforms RetDec and McSema in mangled EXF recovery by 96.4% and 97.3% on SPECrate 2017.Furthermore, we delve deeper into static binary translation and address several cross-ISA EXFC problems. When integrated with McSema, EFACT correctly translates 36.7% more benchmarks from x86-64 to x86-64 and 93.6% more from x86-64 to AArch64 than McSema alone on EEMBC.
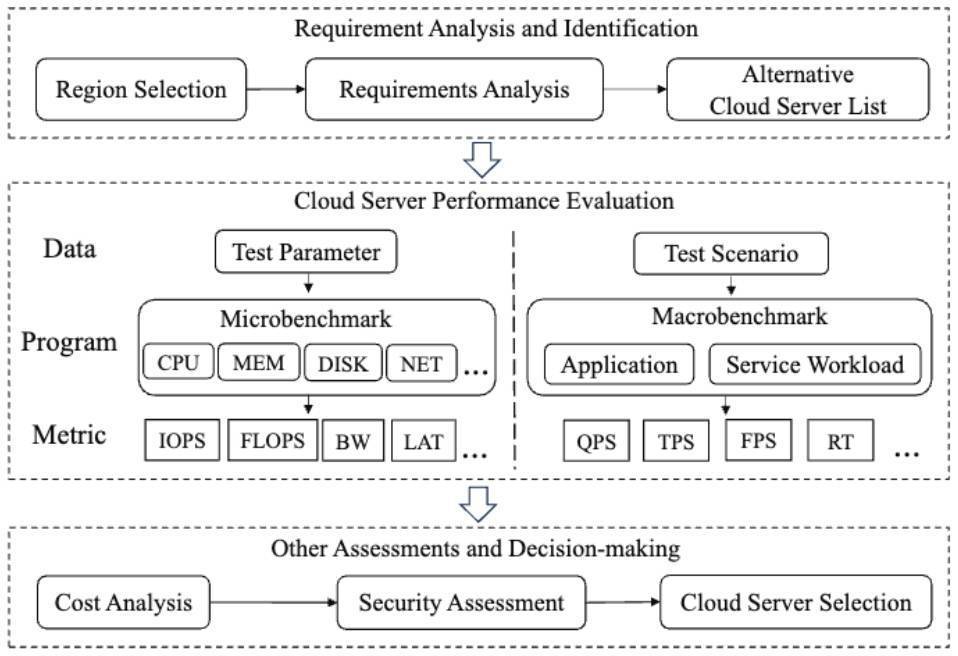
Hmem: A Holistic Memory Performance Metric for Cloud Computing
International Symposium on Benchmarking, Measuring and Optimization
·
14 Feb 2024
With the proliferation of cloud computing, cloud service providers offer users a variety of choices in terms of pricing and computing performance. A critical factor impacting computing performance is main memory, often evaluated using bandwidth and access latency metrics. For two evaluations with the same workload while under different system configurations, it is hard to determine which system delivers better memory performance for the particular workload if neither evaluation data achieves higher bandwidth and lower latency simultaneously. This dilemma is further exacerbated under different memory access patterns. We recognize that state-of-the-art memory performance metrics cannot well address the dilemma. To address this challenge, we define a holistic memory performance metric, named Hmem, which is calculated from a fusion of bandwidth and latency metrics across different access patterns. To reflect the overall performance of a given workload, we calculate the correlation between our proposed metric and the workload’s throughput. Experimental results show that Hmem exhibits an average improvement of 70% on correlation coefficients compared to state-of-the-art memory performance metrics. A large cloud service provider has adopted Hmem to improve the efficiency of their memory performance evaluation and cloud server selection.
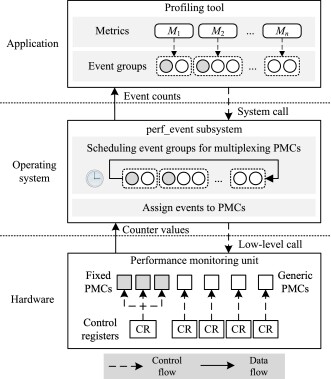
Efficient Cross-platform Multiplexing of Hardware Performance Counters via Adaptive Grouping
ACM Transactions on Architecture and Code Optimization
·
19 Jan 2024
Collecting sufficient microarchitecture performance data is essential for performance evaluation and workload characterization. There are many events to be monitored in a modern processor while only a few hardware performance monitoring counters (PMCs) can be used, so multiplexing is commonly adopted. However, inefficiency commonly exists in state-of-the-art profiling tools when grouping events for multiplexing PMCs. It has the risk of inaccurate measurement and misleading analysis. Commercial tools can leverage PMCs, but they are closed source and only support their specified platforms. To this end, we propose an approach for efficient cross-platform microarchitecture performance measurement via adaptive grouping, aiming to improve the metrics’ sampling ratios. The approach generates event groups based on the number of available PMCs detected on arbitrary machines while avoiding the scheduling pitfall of Linux perf_event subsystem. We evaluate our approach with SPEC CPU 2017 on four mainstream x86-64 and AArch64 processors and conduct comparative analyses of efficiency with two other state-of-the-art tools, LIKWID and ARM Top-down Tool. The experimental results indicate that our approach gains around 50% improvement in the average sampling ratio of metrics without compromising the correctness and reliability.
2023
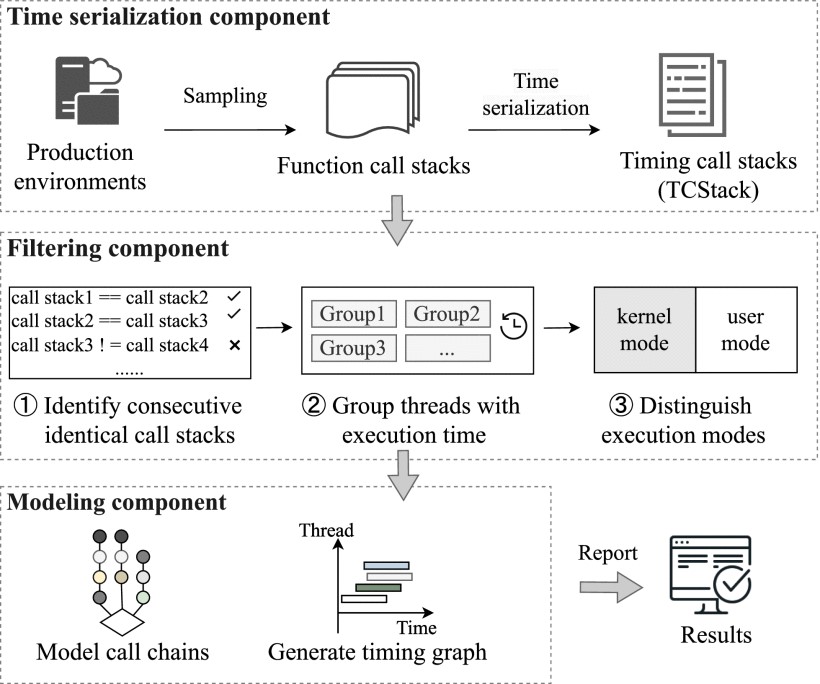
TCSA: Efficient Localization of Busy-Wait Synchronization Bugs for Latency-Critical Applications
IEEE Transactions on Parallel and Distributed Systems
·
13 Dec 2023
Busy-wait synchronization is often used for latency-critical applications to ensure low latency. Unfortunately, its performance bugs due to thread contention may lead to request failures or even system crashes. Localizing the performance bugs of busy-wait synchronization is not trivial because we have to pinpoint the exact moment of occurrence from a relatively long measurement period and simultaneously identify candidate busy-wait threads from numerous concurrent threads. Existing methods often rely on hotspot-driven analysis of lock-related functions, but they still need extensive manual work to localize busy-wait threads. This paper proposes timing call stack analysis (TCSA), an efficient approach to localizing busy-wait synchronization bugs. The key idea is to time-serialize the function call stacks of applications and identify consecutive identical call stacks to catch busy-wait threads. TCSA can handle any application regardless of its programming language and identify various busy-wait patterns, including spinlocks, chaining spinlocks, futexes, and safepoint checks within the Java Virtual Machine. Compared to the state-of-the-art, TCSA can effectively diminish the quantity of examined records (e.g., threads and functions) by 1 to 3 orders of magnitude. TCSA has been deployed to a large cloud service provider, demonstrating its effectiveness, efficiency, and practicality in four real latency-critical applications.
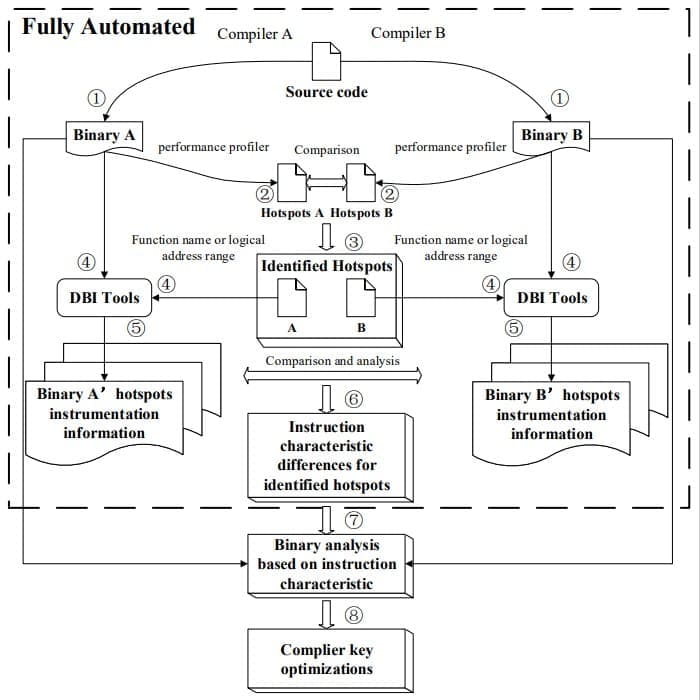
A Hotspot-Driven Semi-automated Competitive Analysis Framework for Identifying Compiler Key Optimizations
Proceedings of the 32nd ACM SIGPLAN International Conference on Compiler Construction
·
17 Feb 2023
High-performance compilers play an important role in improving the run-time performance of a program, and it is hard and time-consuming to identify the key optimizations implemented in a high-performance compiler with traditional program analysis. In this paper, we propose a hotspot-driven semi-automated competitive analysis framework for identifying key optimizations through comparing the hotspot codes generated by any two different compilers. Our framework is platform-agnostic and works well on both AArch64 and X64 platforms, which automates the stages of hotspot detection and dynamic binary instrumentation only for selected hotspots. With the instrumented instruction characterization information, the framework users can analyze the binary code within a much smaller scope to explore practical optimizations implemented in any of the compilers compared. To demonstrate the effectiveness and practicality, we conduct experiments on SPECspeed 2017 Integer benchmarks(CINT2017) and their binaries generated by open-source GCC compiler versus proprietary Huawei BiSheng and Intel ICC compilers on AArch64 and X64 platforms respectively. Empirical studies show that our methods can identify several significant optimizations that have been implemented by proprietary compilers and as well can be implemented in open-source compilers. To Hangzhou Hongjun Microelectronics Technology(Hjmicro), the identified key optimizations shed great light on optimizing their GCC-based product compiler, which delivers 20.83% improvement for SPECrate 2017 Integer on AArch64 platform.